-
(*: indicates equal contribution.)
|
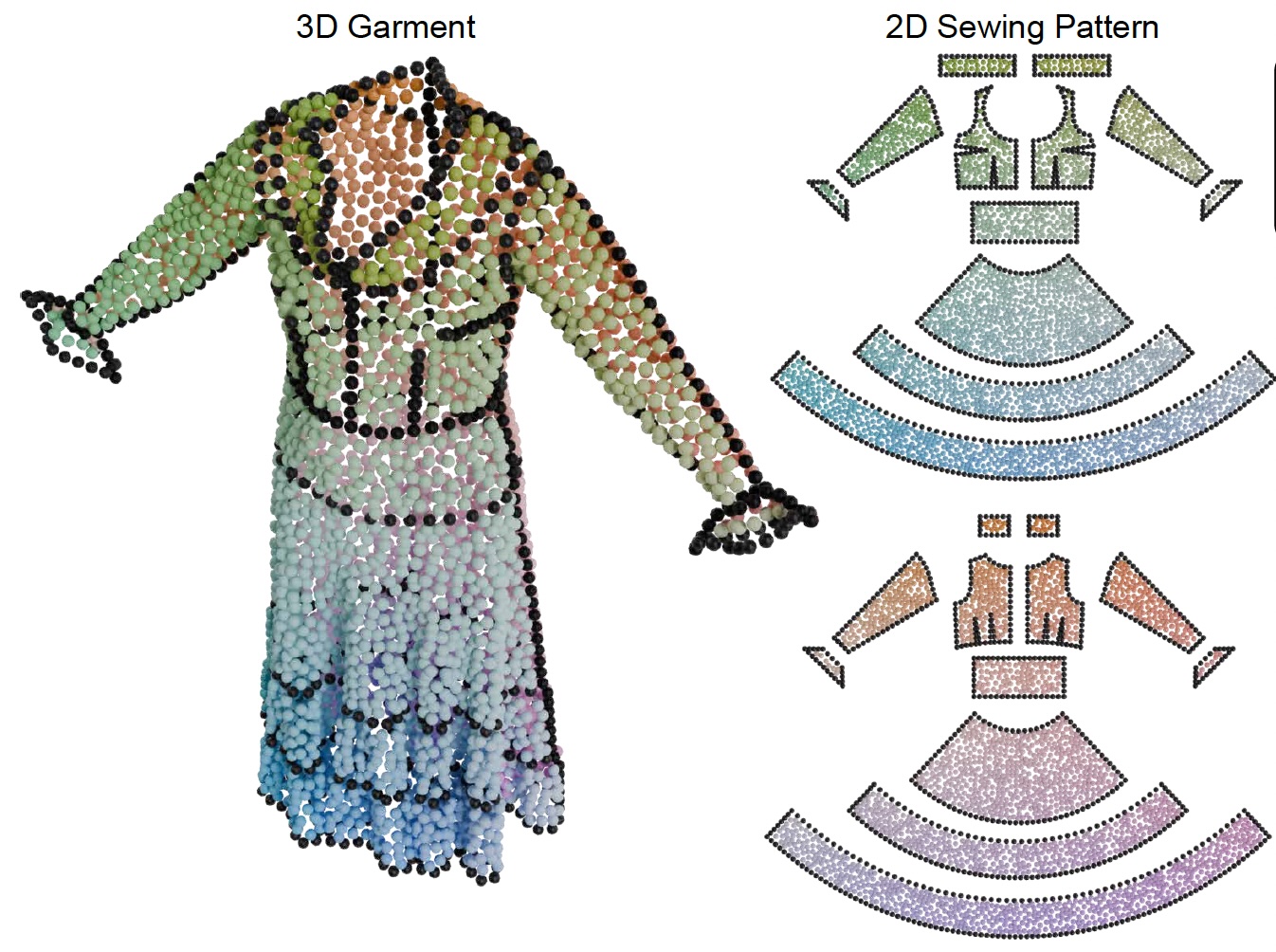
Garment Particles: A Symmetric 2D-3D Point Cloud Representation for Garment GenerationKiyohiro Nakayama, I-Chao Shen, Ruofan Liu, Yiming Wang, Gordon Wetzstein, Takeo IgarashiSIGGRAPH 2026 Conference Track Garment Particles is a garment representation that models both the sewing pattern and its draped garment geometry in a symmetric, 2D–3D point cloud. (a) shows the garment particles representation. The color on the 3D garment (left) and the 2D sewing pattern (right) indicate the same points. Garment Particles Flow (GPF), a generative framework, generates garment particles from multimodal inputs. More importantly, the prior space of GPF enables versatile editing in both 3D garment geometry and 2D sewing pattern domains. Finally, Particles-to-Pattern Flow (PPF) converts the generated particles to simulation-ready sewing patterns. (b) shows the various editing applications enabled by GPF. [Project] [Video] [Paper] [Code] [Dataset] |
|
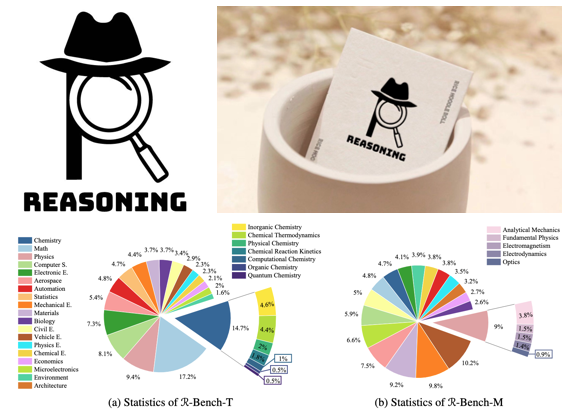
RBench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning EvaluationMeng-Hao Guo, Jiajun Xu, Yi Zhang, Jiaxi Song, Haoyang Peng, Yi-Xuan Deng, Xinzhi Dong, Kiyohiro Nakayama, Zhengyang Geng, Chen Wang, Bolin Ni, Guo-Wei Yang, Yongming Rao, Houwen Peng, Han Hu, Gordon Wetzstein, Shi-Min HuICML 2025 Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here. [Project] [Paper] [Dataset] |
>
|
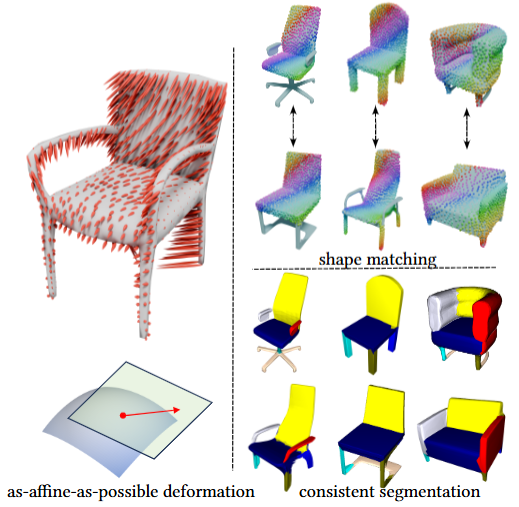
GenAnalysis: Joint Shape Analysis by Learning Man-Made Shape Generators with Deformation Regularizations.Yuezhi Yang, Haitao Yang, Kiyohiro Nakayama, Xiangru Huang, Leonidas J. Guibas, Qixing HuangSIGGRAPH (Journal) 2025 We introduce GenAnalysis, an implicit shape generation framework that allows joint analysis of a collection of man-made shapes. GenAnalysis innovates in learning an implicit shape generator to reconstruct a continuous shape space from the input shape collection. It offers interpolations between pairs of input shapes for correspondence computation. It also allows us to understand the shape variations of each shape in the context of neighboring shapes. Such variations provide segmentation cues. A key idea of GenAnalysis is to enforce an as-affine-as-possible (AAAP) deformation regularization loss among adjacent synthetic shapes of the generator. This loss forces the generator to learn the underlying piece-wise affine part structures. We show how to extract data-driven segmentation cues by recovering piece-wise affine vector fields in the tangent space of each shape and how to use this generator to compute consistent inter-shape correspondences. These correspondences are then used to aggregate single-shape segmentation cues into consistent segmentations. Experimental results on benchmark datasets show that GenAnalysis achieves state-of-the-art results on shape segmentation and shape matching. [Paper] |
|
AIpparel: A Large Multimodal Generative Model for Digital GarmentsKiyohiro Nakayama*, Jan Ackermann*, Timur Levent Kesdogan*, Yang Zheng, Maria Korosteleva, Olga Sorkine-Hornung, Leonidas J. Guibas, Guandao Yang, Gordon WetzsteinCVPR 2025 Apparel is essential to human life, offering protection, mirroring cultural identities, and showcasing personal style. Yet, the creation of garments remains a time-consuming process, largely due to the manual work involved in designing them. To simplify this process, we introduce AIpparel, a large multimodal model for generating and editing sewing patterns. Our model fine-tunes state-of-the-art large multimodal models (LMMs) on a custom-curated large-scale dataset of over 120,000 unique garments, each with multimodal annotations including text, images, and sewing patterns. Additionally, we propose a novel tokenization scheme that concisely encodes these complex sewing patterns so that LLMs can learn to predict them efficiently. AIpparel achieves state-of-the-art performance in single-modal tasks, including text-to-garment and image-to-garment prediction, and it enables novel multimodal garment generation applications such as interactive garment editing. [Project] [Paper] [Code] |
|
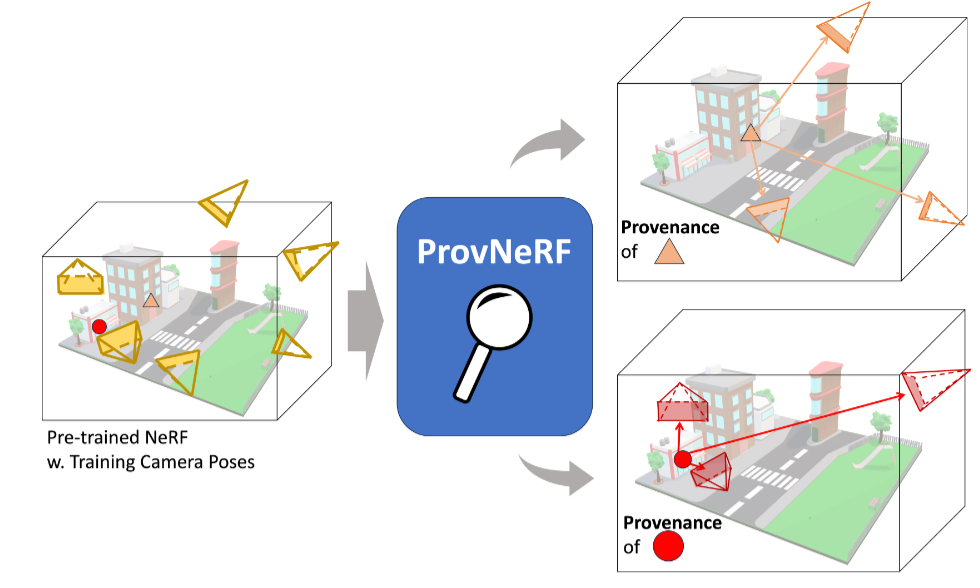
ProvNeRF: Modeling per Point Provenance in NeRFs as a Stochastic ProcessKiyohiro Nakayama, Mikaela Angelina Uy, Yang You, Ke Li, Leonidas J. GuibasAdvances in Neural Information Processing Systems (NeurIPS), 2024 Neural radiance fields (NeRFs) have gained popularity with multiple works showing promising results across various applications. However, to the best of our knowledge, existing works do not explicitly model the distribution of training camera poses, or consequently the triangulation quality, a key factor affecting reconstruction quality dating back to classical vision literature. We close this gap with ProvNeRF, an approach that models the provenance for each point -- i.e., the locations where it is likely visible -- of NeRFs as a stochastic field. We achieve this by extending implicit maximum likelihood estimation (IMLE) to functional space with an optimizable objective. We show that modeling per-point provenance during the NeRF optimization enriches the model with information on triangulation leading to improvements in novel view synthesis and uncertainty estimation under the challenging sparse, unconstrained view setting against competitive baselines. [Project] [Paper] [Code] |
|
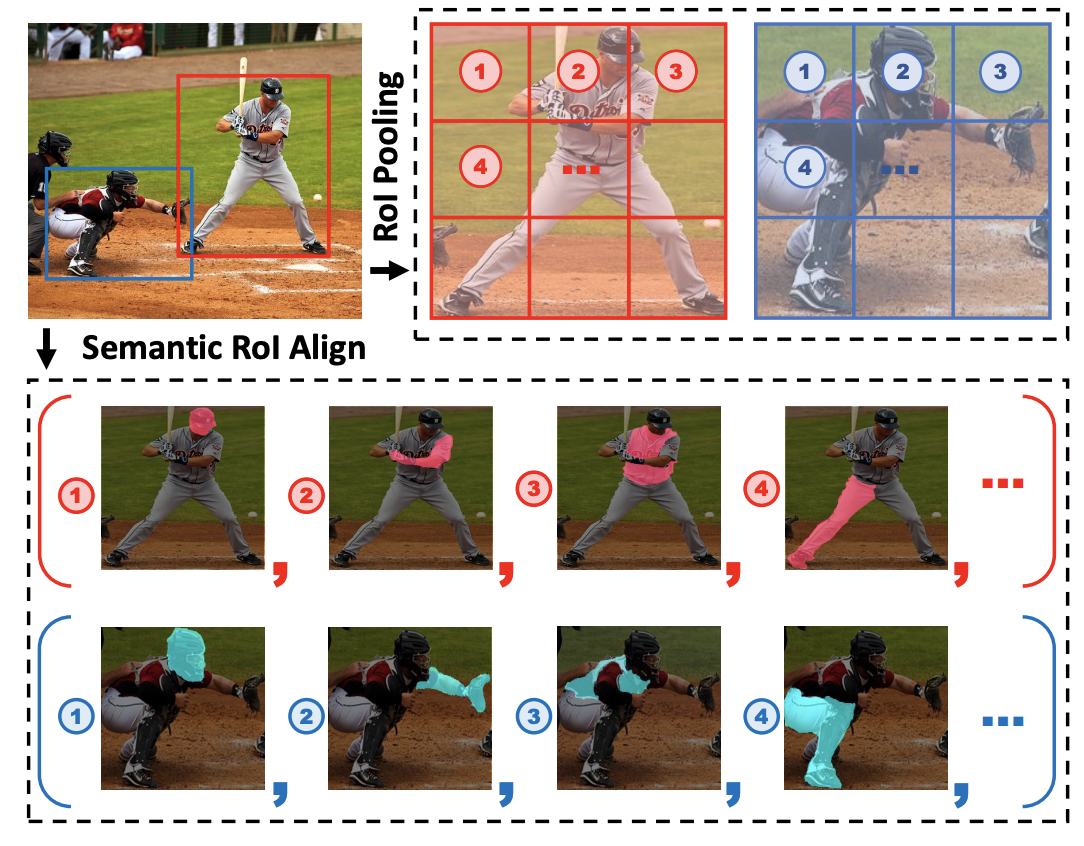
Semantic-Aware Transformation-Invariant RoI AlignGuo-Ye Yang, Kiyohiro Nakayama, Zi-Kai Xiao, Tai-Jiang Mu, Sharon Xiaolei Huang, Shi-Min HuAAAI Conference on Artificial Intelligence, 2024 Great progress has been made in learning-based object detection methods in the last decade. Two-stage detectors often have higher detection accuracy than one-stage detectors, due to the use of region of interest (RoI) feature extractors which extract transformation-invariant RoI features for different RoI proposals, making refinement of bounding boxes and prediction of object categories more robust and accurate. However, previous RoI feature extractors can only extract invariant features under limited transformations. In this paper, we propose a novel RoI feature extractor, termed Semantic RoI Align (SRA), which is capable of extracting invariant RoI features under a variety of transformations for two-stage detectors. Specifically, we propose a semantic attention module to adaptively determine different sampling areas by leveraging the global and local semantic relationship within the RoI. We also propose a Dynamic Feature Sampler which dynamically samples features based on the RoI aspect ratio to enhance the efficiency of SRA, and a new position embedding, i.e., Area Embedding, to provide more accurate position information for SRA through an improved sampling area representation. Experiments show that our model significantly outperforms baseline models with slight computational overhead. In addition, it shows excellent generalization ability and can be used to improve performance with various state-ofthe-art backbones and detection methods. [Paper] |
|
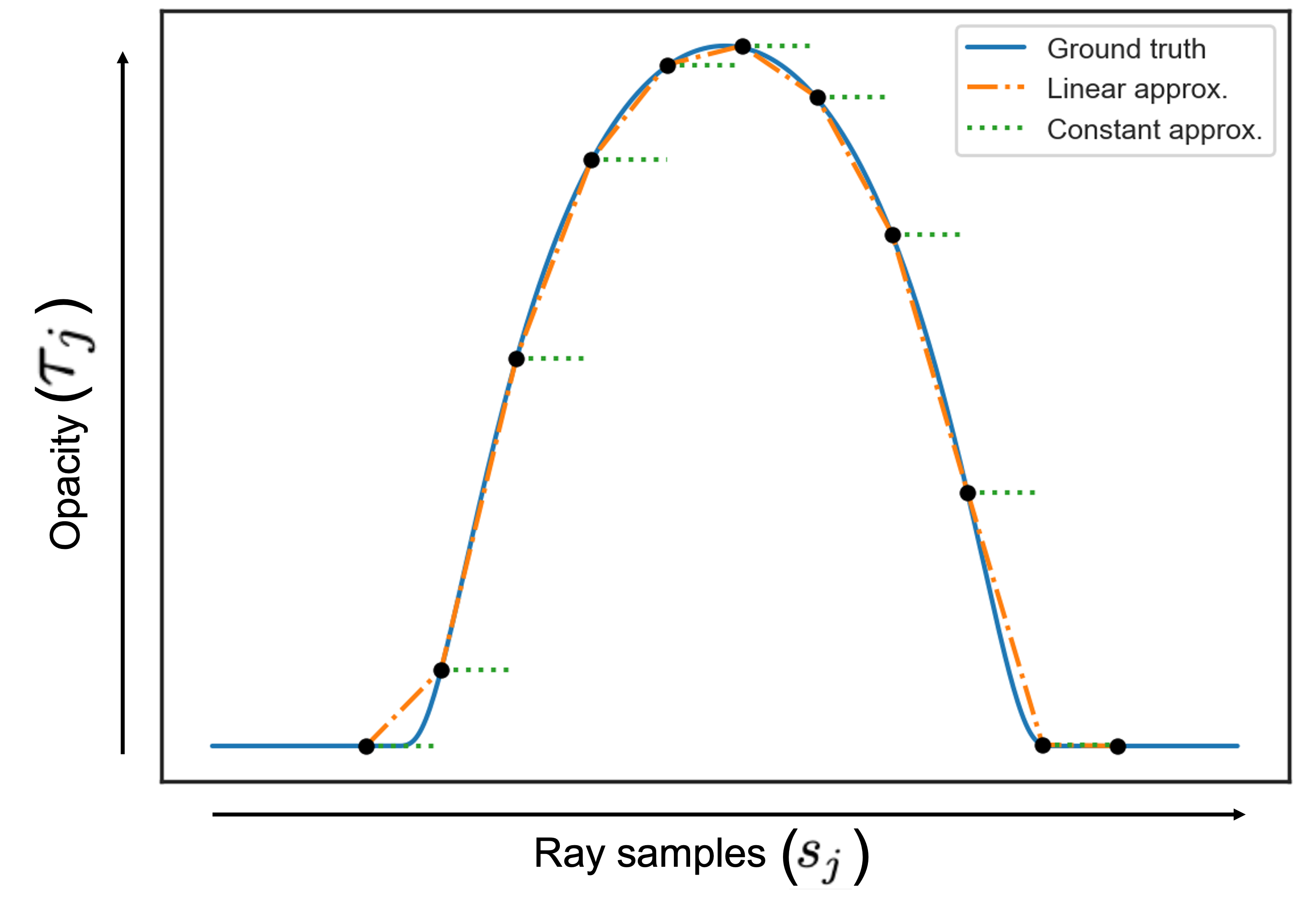
NeRF Revisited: Fixing Quadrature Instability in Volume RenderingMikaela Angelina Uy, Kiyohiro Nakayama, Guangdao Yang, Rahul Krishna, Leonidas J. Guibas, Ke LiAdvances in Neural Information Processing Systems (NeurIPS), 2023 Neural radiance fields (NeRF) rely on volume rendering to synthesize novel views. Volume rendering requires evaluating an integral along each ray, which is numerically approximated with a finite sum that corresponds to the exact integral along the ray under piecewise constant volume density. As a consequence, the rendered result is unstable w.r.t. the choice of samples along the ray, a phenomenon that we dub quadrature instability. We propose a mathematically principled solution by reformulating the sample-based rendering equation so that it corresponds to the exact integral under piecewise linear volume density. This simultaneously resolves multiple issues: conflicts between samples along different rays, imprecise hierarchical sampling, and non-differentiability of quantiles of ray termination distances w.r.t. model parameters. We demonstrate several benefits over the classical sample-based rendering equation, such as sharper textures, better geometric reconstruction, and stronger depth supervision. Our proposed formulation can be also be used as a drop-in replacement to the volume rendering equation for existing methods like NeRFs [Project] [Paper] [Code] |
|
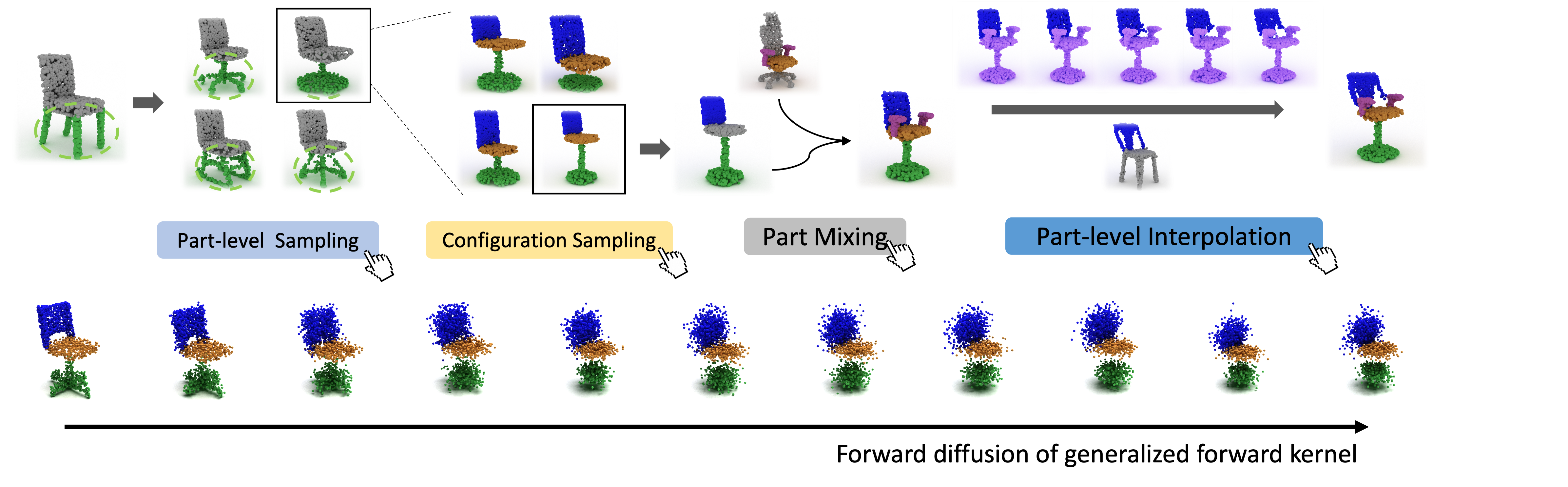
DiffFacto: Controllable Part-Based 3D Point Cloud Generation with Cross DiffusionKiyohiro Nakayama, Mikaela Angelina Uy, Jiahui Huang, Shi-Min Hu Ke Li Leonidas J. GuibasIEEE International Conference on Computer Vision (ICCV), 2023 We introduce DiffFacto, a novel probabilistic generative model that learns the distribution of shapes with part-level control. We propose a factorization that models independent part style and part configuration distributions, and present a novel cross diffusion network that enables us to generate coherent and plausible shapes under our proposed factorization. Experiments show that our method is able to generate novel shapes with multiple axes of control. It achieves state-of-the-art part-level generation quality and generates plausible and coherent shape, while enabling various downstream editing applications such as shape interpolation, mixing and transformation editing. [Project] [Paper] [Code] |